该论文的思路主要是考虑使用确定性的环境进行训练找到一个可行解,然后使用随机探索的测试,通过鲁棒化操作让随机探索更加可靠。目前尚未进行复现,但是关于这篇论文论坛上的争议很大,其实验结果可靠性有待验证,不过是一个很有趣的思路,文中说这是一个框架性的研究,许多细节可以进行深入挖掘。论文中确定性训练部分并没有使用神经网络,与传统的RL的做法有所不同,其开源代码与具体的环境交联很大,需要一定时间消化一下。

一、概述
1.1 Hard-Exploration Problems的定义
- 稀疏回报(sparse)
- 误导回报(deceptive)
1.2 之前的解决方法存在的问题
之前的方法一般是采用内部激励(Intrinsic Motivation[IM])给智能体提供一些内在回报intrinsic rewards(IRs),去激励他们去探索。常用的手段有curiosity,novelty-seeking。但是其表现并不是很好,作者给出了表现不好的两个原因detachment 和 derailment
Detachment:
- Detachment是指由IM驱动的agent可能脱离高内在奖励(IR)的边界;
- 假设内在奖励是一种消耗性资源,agent会在一个内在奖励高的区域集中消耗内在奖励,当其消耗殆尽很难重新发现agent在初始区域中的分离边界,由于灾难性遗忘(catastrophic forgetting) agent 可能不会记得如何回到那个边界;
- 每次这个过程发生时,潜在的探索途径都可能会丢失,或者至少很难重新发现。在最坏的情况下,当前policy所访问的状态空间区域附近可能缺乏剩余的IR(即使其他地方可能存在大量的IR),因此没有任何学习信号可以指导agent进一步有效探索的方式;
- 随着时间的推移,可以慢慢地增加内在奖励,但是整个无效的过程可以无限重复;
- 理论上讲, replay buffer 可以防止 detachment,但实际上它必须很大,以防止有关abandoned边界的数据在需要之前不被清除,大的 replay buffer 引入它们自己的优化稳定性困难(参考sutton的分析);
- Go-Explore算法通过显式存储所访问的有希望状态的存档来解决detachment的问题,以便随后可以重新访问和探索它们。
Derailment:
当agent发现了一个有希望的状态(promising state)时,可能会发生偏离(Derailment),返回该状态并从中进行探索是有益的;
典型的RL算法试图通过运行可以回到初始状态的策略来实现这种期望的行为,并对现有策略的加入一些随机扰动以鼓励其产生略微不同的行为(例如,进一步探索 exploring further);
加入随机扰动的原因是因为IM agetn有两层探索机制
- 在达到新状态时奖励的高层IR激励;
- 更基本的探索机制,如epsilon-greedy探索,动作空间噪声或参数空间噪声;
IM agent依赖第二种探索机制进行高IR状态的探索,而依赖于第一种机制回到高IR状态;
然而,为了达到先前发现的高IR状态,需要一系列更长,更复杂和更精确的动作,这种随机扰动将更有可能“破坏(Derail)”agent不再返回那个状态。这是因为所需的精确动作被basic探索机制天真地扰乱,导致agent很少成功地达到它所记录的已知状态,并且进一步探索可能是最有效的;
为了解决Derailment问题,Go-Explore的一个见解是,在进一步探索之前,有效的探索可以分解为第一次回到有希望的状态(无需有意添加任何探索)。
1.3 Go-Explore概述
方案优势
解决了一下detachment和derailment的问题,并且提出了在随机环境下的鲁棒的解决方案。
方案概述:
- phase1: 首先用一个比较简单的方法,用一个确定性的方法来解决问题,即发现如何解决问题;
- phase2: 然后进行鲁棒化(即训练在存在随机性的情况下能够可靠地执行的解决方案)。
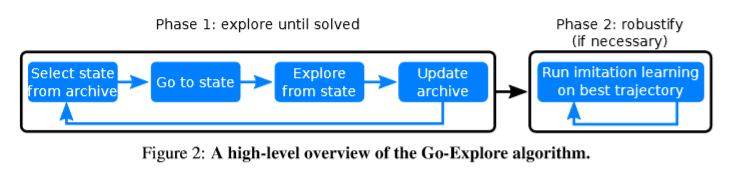
【phase1】 寻找少见的state形成解决系数回报或者误导回报问题的基本解决方案,phase1 使用两种策略,通过记录状态和到达状态的方式来解决detachment还有derailment的问题:
(1) 将到目前为止所有访问过的不同的状态存下来
(2) 每次选择存储池(archive)中选择一个状态进行探索 ,
首先【Go back】回到这个状态(不加任何随机探索),
然后【Explore】从这个状态开始进行探索新的state。因而算法框架称为Go-Explore。
作者举搜索房屋的例子说明了phase1和IM探索的区别:
IM算法类似于在房子中搜索一个射灯,它在房子的一个区域中投射出一束狭窄的探测光束,然后是另一个区域,另一个区域,以及另一个区域,等等,随着光被吸引到其非常小的可见区域边缘的IM区域。如果在任何一点上光束不能落在任何具有IM的区域上,它就会迷失。 Go-Explore更像是在房子的一个房间,然后是相邻的房间,然后是相邻的房间等等,直到整个房子都被照亮。因此,Go-Explore将逐步扩展其所有方向的知识范围,直到找到解决方案。
【phase2】 通过imitation learning的方式进行鲁棒化,与正常的模仿学习的方式不同,Go-Expolore的方法使用的不是人工demonstration而是由phase1生成的demonstration。该阶段的输入是一个或多个回报较高的trajectory,输出是一个能够达到相似表现能力的鲁棒的策略。
二、 Go-Explore 算法
算法的主要思路是围绕着如何可靠的记录并且回到promising state。以此为思路可以扩展很多算法。
2.1 Phase1 探索直到问题解决
Phase1 存储不同的interesting states,论文中称为”Cell”, 并且存储能够到达这些状态的trajectory。
开始的时候只包含初始状态,然后不断重复以下步骤:
(1) 从当前archive中选择一个cell
(2) 回到cell的状态,并且不加任何随机扰动
(3) 从cell状态进行随机探索
(4) 新出现的cell和到达cell的trajectory将加入archive中
2.1.1 Cell 表示
理论上,人们可以直接在高维状态空间(其中每个Cell正好包含一个状态)中进行run-go探索;然而,这样做在实践中是很难做到的。为了能够在像Atari这样的高维状态空间中进行处理,Go Explore的第一阶段需要一个较低维的空间来进行搜索(尽管最终策略仍将在相同的原始状态空间中发挥作用,在本例中是像素)。因此,单元表示应该合并相似的状态,而不是合并有意义的不同的状态。
这样,一个好的Cell表示应该将观测的维数减少到一个有意义的低维空间。丰富的文献研究如何从像素获得良好的表示。一种选择是从传统的RL算法训练的神经网络中间提取latent code,最大化外在和/或内在motivation,可选地添加辅助任务,如预测奖励。其他选项包括无监督技术,如自动编码或预测未来状态的网络,以及其他辅助任务,如像素控制。
在未来的工作中使用Go-Explore测试这些技术很有趣,对于这些使用Go-Explore的初始实验,我们使用两种不同的表示来测试其性能:一种是不利用对特定游戏的领域知识,另一种则利用易于提供的领域知识。
不使用domain knowledge
在蒙特祖玛的复仇里面,论文采用的是(1)将每帧的图像转为灰度图(2)使用线性插值将灰度图downscale为11x8(3)将像素密度由0~255缩放到0~8之间。
使用domain knowledge
在蒙特祖玛的复仇中,领域知识表示为:agent的xy位置(使用16x16网格离散化), 房间数目,level数,找到钥匙的房间等。
在Pitfall中,领域知识表示为:agent的xy位置,以及房间数
所有这些信息都是用简单的手工编码分类器直接从像素中提取出来的,以检测诸如主要角色的位置等对象,并结合我们对两个游戏中地图结构的了解。虽然Go Explore提供了在第一阶段的cell表示中利用领域知识的机会,但是第二阶段产生的机器人化神经网络仍然只从像素直接播放。
2.1.2 选择Cell
在第一阶段的每一次迭代中,都会从archive中选择一个Cell进行探索。这种选择可以使用均匀分布随机地进行,但在许多情况下,我们可以通过创建(或学习)一个启发式的方法来改进基线,使某些Cell优于其他Cell。在初步实验中,我们发现这种启发式方法可以提高均匀随机抽样的性能。具体的启发式定义根据所解决的问题而不同,但在较高的层次上,论文中的启发式为每个被认为更promising的Cell分配一个更高的正权重。例如,由于没有经常被访问,所以这个Cell状态是首选的,这有助于发现一个新的Cell,或期望可以接近未发现的Cell。将所有Cell的权重归一化,以表示下一个选择的每个Cell的概率。没有一个Cell的权重等于0,所以原则上所有单元都可以继续进行进一步的探索。(关于启发式算法细节在后文有详细说明)
2.1.3 利用确定性的Simulator返回到Cell状态
Go-Explore的一个主要原则是,在从一个Cell进行探索之前,先返回一个Promising cell,而不需要进行额外的探索。Go-Explore的哲学是,考虑到问题的限制,我们应该尽可能容易地回到那个Cell。返回到一个Cell的最简单的方法是,如果世界是确定的和可重置的,这样就可以将Simulator的状态重置为以前访问该Cell的状态。
这里作者提出了两个思路:一个是仅在测试的时候允许随机,第二个是在训练和测试的时候都可以随机。
- 仅在测试的时候允许随机
由于当前的RL算法可以采取unsafe的action并需要大量的经验来学习,因此在可预见的将来,RL的大部分应用可能需要在模拟器中进行训练,然后才能转移到现实世界(并可选择在现实世界中进行微调)。例如,在将解决方案转移到现实世界之前,大多数机器人学习算法在模拟器中训练;这是因为直接在机器人上学习速度慢、采样效率低、可能会损坏机器人,并且可能不安全。幸运的是,对于许多领域,模拟器都是可用的(例如,机器人模拟器、交通模拟器等)。Go-Explore的一个观点是,我们可以利用这样一个事实,即可以使模拟器具有确定性来提高性能,特别是在困难的探索问题上。对于许多类型的问题,我们需要一个可靠的最终解决方案(例如,一个在自然灾害后能够可靠地找到幸存者的机器人),并且没有理论性的理由去关心我们是否通过最初的确定性训练获得这个解决方案。如果我们能够解决以前无法解决的问题,包括在评估(测试)时是随机的问题,通过使模拟器具有确定性,我们应该利用这个机会。
- 在训练过程中也需要随机
由于某些情况下无法提供仿真环境,导致算法必须在training的时候使用随机探索。对于这种情况Go-Explore算法也可以应对,其通过训练 goal-conditioned 策略(HER, Universal value function approximators ),该策略能够在探索阶段可靠地返回到archive中的cell,这是一个值得研究的方向。虽然计算成本要高得多,但这种策略会在探索阶段结束时产生完全训练有素的policy,这意味着最终不需要鲁棒化阶段。这里存在一些问题,其中环境具有随机性的形式,阻止算法可靠地返回到特定cell,无论agent采取何种action(例如,在扑克中,没有可靠的行动顺序导致您进入你有两个ace的状态)。
考虑到上述的两种模式,我们现在可以问蒙特祖玛的复仇与陷阱是否代表第一类(我们关心的所有都是对测试时随机性具有鲁棒性的解决方案)或第二类领域(算法必须处理训练时随机性的情况)。本文中的所有结果和声明均适用于在训练期间不需要随机性的版本(即仅在评估期间需要随机性)。在训练是随机的时候应用Go-Explore仍然是不久的将来一个令人兴奋的研究途径。
论文在实验过程中,并没存储到cell的序列,只存了cell可以提高运算效率
2.1.4 从Cell状态开始探索
到达Cell状态后,可以应用任何探索方法来寻找新Cell。在这项工作中,agent通过对$k = 100$个训练帧进行随机动作进行探索,在每个训练帧中重复前一个动作的概率为95%(允许agent采取行动的帧,因此不包括任何跳过的帧由于frame skip)。除了达到$k = 100$训练框架的探索限制之外,探索也会在episode结束时中止,导致episode结束的动作将被忽略,因为它不会产生目标Cell。
有趣的是,这种探索不需要神经网络或其他控制器,实际上在本文的任何实验中都没有使用神经网络进行探索阶段(阶段1)(直到第2阶段才开始训练神经网络)。完全随机探索如此有效的事实凸显了在进一步探索之前简单地回到promising Cell的惊人力量,尽管我们认为智能地探索(例如通过训练有素的政策)可能会改善我们的结果并且是未来的研究方向。
2.1.5 更新存储archive
更新的两种情况:
agent访问了没在archive中出现过的cell
此时需要存储agent如何到达这个cell 的整个trajectory,当前cell的状态,trajectory的累积回报,trajectory的长度。
新的能到达已存在于archive中cell的trajectory 比之前的trajectory好
好的定义:new trajectory 的分数较高,同等分数时new trajectory的长度较短
此外,将重置影响选择该Cell可能性的信息,包括选择该Cell的总次数和从发现另一个Cell以来选择该Cell的次数。当Cell合并了许多不同的状态时,重置这些值是有益的,因为到达Cell的新方法实际上可能是一个更有前景的垫脚石(因此我们希望鼓励选择它)。我们不重置记录访问Cell次数的计数器,因为这将使最近发现的Cell与最近更新的Cell不可区分,并且最近发现的Cell(即访问计数较低的Cell)更有希望进行探索,因为它们很可能接近我们不断扩大的知识领域的表面。
因为细胞合并了许多状态,所以我们不能保证,如果用一种不同的、更好的方式从A到B,从起始状态 A到 Cell B到 Cell C的trajectory仍然会到达 C;因此,到达Cell的更好的方法并没有被整合到建立在原始轨道上的其他Cell的轨道中。这里还有待研究。
2.2 Phase2: 鲁棒化
如果成功,阶段1的结果是一个或多个高性能的trajectory。然而,如果Go探索的第一阶段在模拟器中利用了确定性,那么这样的轨迹对于测试时出现的任何随机性都不具有鲁棒性。第2阶段通过imitation learning 创建一个对噪音具有鲁棒性的策略来解决这一差距。重要的是,在第2阶段中增加了随机性,以便最终策略对其在测试环境中评估时所面临的随机性具有鲁棒性。因此,正在training的policy必须学习如何模拟和/或执行,以及从Go-Explore勘探阶段获得的轨迹,同时处理原始轨迹中不存在的情况。根据环境的随机性,这种调整可能具有很高的挑战性,但是比起从头开始尝试解决稀疏的奖励问题要容易得多。
虽然大多数模仿学习算法可以用于第2阶段,但不同类型的模仿学习算法可以定性地影响最终的策略。试图接近模拟演示行为的LFD算法可能难以改进。为此,我们选择了一个已经证明可以改进的LFD算法:Salimans和Chen提出的反向算法。它的工作原理是在轨迹中的最后一个状态附近启动agent,然后从那里运行一个普通的RL算法(ppo)。一旦算法学会从接近轨迹末端的起始位置获得与示例轨迹相同或更高的奖励,该算法将代理的起始点沿轨迹备份到稍早的位置,并重复该过程,直到最终代理学会获得大于或等于从初始状态开始的整个示例轨迹。请注意,Resnick等人在大约同一时间独立发现了类似的算法。
虽然这种机器人化方法有效地将专家轨迹视为代理的课程,但该策略只进行优化,以最大限度地提高自己的分数,而不是被迫准确地模拟轨迹。由于这个原因,这个阶段能够进一步优化专家的轨迹,并在它们之外进行归纳,这两个都是我们在实验中实际观察到的(第3节)。除了寻求比原始轨迹更高的分数之外,由于它是一种带有折扣因子的RL算法,因此对短期奖励的奖励比之后收集的奖励多,因此它还具有提高奖励收集效率的压力。因此,如果原始轨迹包含不必要的动作(如访问死角和返回),那么在机器人化过程中可以消除这种行为(我们也观察到这种现象)。
