一、 概述
1.1 解决的问题
Crowd-Robot Interaction (CRI), 开源地址
1.2 先前方法总结
存在的问题
- 人群的集体影响通常是由成对相互作用的简化集合建模的,例如Maximin运算符或LSTM,它可能无法完全表示所有的相互作用。
- 大多数方法只关注从人到机器人的单向交互,而忽略了人群中可能间接影响机器人的交互。
已有的方法
【第一类基于人工设计函数】
Social Force
Interacting Gaussian Process (IGP):
将每个agent的traj建模为一个独立的高斯过程,并提出一个相互作用势项来结合单个的高斯过程,进行相互作用。
【第二类基于Imitation Learning】
- BC
- IRL
- GAIL
【第三类基于强化学习】
本文的方法
- 用self-attention mechanism重新思考人-机器人的配对互动
- 在强化学习框架中联合建模Human-Robot和Human-Human 交互
1.3 问题的建模
robot从n个人的人群中穿越到目标点。
对于每一个agent(人和机器人),已知:
【可相互观测】位置$p=[p_x,p_y]$,速度$v=[v_x,v_y]$,半径$r$
【不可观测】目标位置$p_g$,期望速度$v_{pref}$
【假设】robot的速度$v_t$,在执行action $a_t$ 后可以即时获得,$s_t$ 表示robot的状态,$w_t=[w_t^1,w_t^2…w_t^n]$表示人的状态,Human-Robot联合状态可以表示为:$s_t^{jn}=[s_t,w_t]$
【最优策略的定义】$\pi^*(s_t^{jn}):s_t^{jn}→a_t$
【回报定义】$d_t$为$[t-\Delta t,t]$之间的robot与human的最小间隔
1.4 价值网络训练
基于TD、Replay buffer、target net。

1-3行使用demonstration experience 进行 imitation learning 初始化
4-14行 使用强化学习进行学习
7行的下一时刻状态,使用的是通过仿真获得的真实值,而非通过线性模型进行估计,减少动态模型误差带来的影响。
- 状态转移概率可以使用trajectory prediction model进行估计
价值网络模型需要精确地近似最优价值函数$V$,该函数隐式地encode了agent之间的social coorperation。以前的工作并没有模拟人群交互,这降低了对人口稠密场景的价值估计的准确性。
二、 方法
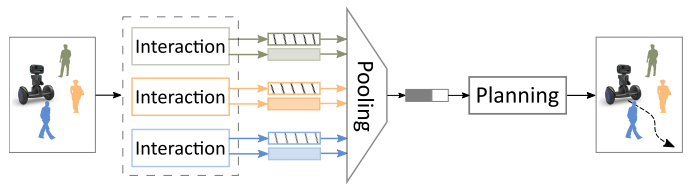
2.1 基本结构
Interaction module
对Human-Robot 交互进行显式建模,并通过粗粒度局部映射对Human-Robot进行encode。
Pooling module
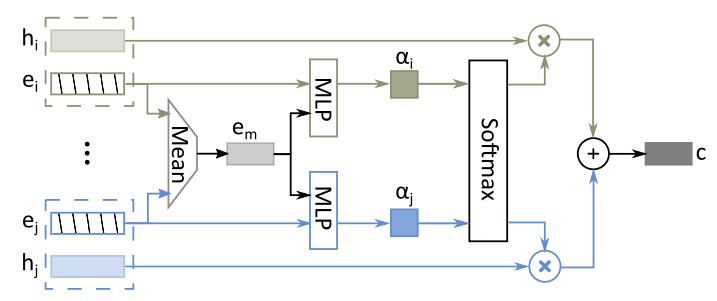
通过self-attention制将相互作用聚合成固定长度的嵌入向量。
Planning module
估计robot和human联合状态对social navigation的value。
2.2 详细模块说明
2.2.1 Parameterization
使用 robot-center parameterization。 以robot所在位置为中心,以当前位置到目标位置的向量方向为x轴。以此进行建模得到的robot及human的states如下:
其中 $d_g=||p-p_g||_2$ 表示robot到目标点的距离,$d_i=||p-p_i||_2$代表robot与neighbor $i$ 之间的距离。
2.2.2 Interaction Module
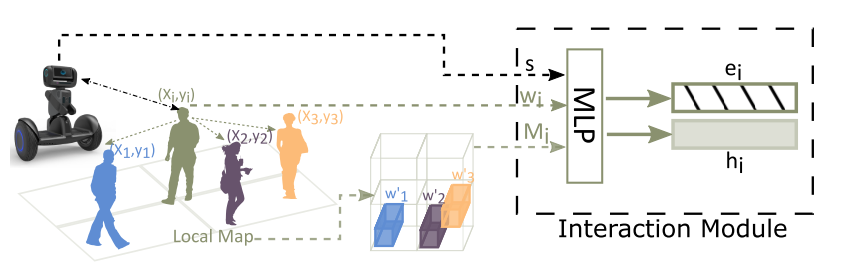
如果考虑相互间的交互,那么算法的时间复杂度较高是$O(n^2)$的,本文使用local map 表示粗粒度的human-human的交互。
构建local map 特征
假设neighbor大小为$L$, 那么以每个human $i$ 为中心构建一个$L×L×3$大小的 tensor $M_i$, 来encode neighbor的位置及速度特征。
构建 embedded encode
使用human的state, map tensor以及 robot state 构建embedded vector $e_i$ (固定长度),这里用一个MLP
2.2.3